
AI-Powered Enterprise Digital Twins
How we created an intelligent digital twin using generative AI and knowledge graphs.
Tolga Üge, Hieu Dang
21.10.2025
In this post, we provide insight into the development of a digital twin based on a company's knowledge graph that interacts with generative AI.
The goal: to make complex relationships within organizations visible and usable—in real time, in dialogue, in context.
Our Vision: An Enterprise Digital Twin You Can Actually Talk To
Imagine you could talk to your company.
You ask a question and get an informed answer that draws on current knowledge from all areas of the business. Whether it's about processes, systems, or organizational units, your company knows the answer in seconds. Because there is a digital enterprise twin that knows all this and talks to you.
That is precisely our vision: a living, talking knowledge graph that maps your enterprise in all its facets. Available via a simple language interface. Anchored in a structured data model. Powered by generative AI.
The Starting Point: Many Questions, One Goal
As digital transformation consultants, we have been working for years on how companies can become “smarter” with their processes and structures with the help of information technology. We see ourselves as “transformation architects” who analyze, redesign, and transform enterprises.
Our most important tools are visual models and simulations, which we use to make companies and planned changes as tangible as possible.
With the advent of powerful language models such as GPT, we wanted to test how our transformation methodology could be supported and further developed by AI.
Initially, there was no specific application—just a question:
Can we design a business model in such a way that an AI assistant can work with it?
To test this, we modeled a fictional car-sharing company and developed an AI assistant that can interact with this model: check it out on Metapad.
The First Model: Simple But Structured
We started with basic elements:
- The enterprise with clear goals
- The organization with departments and teams
- Services provided by the enterprise
- Processes that implement these services
- Activities that make up processes
- IT systems that support these activities
Our goal: a simple but logical model that links processes, roles, and IT systems.
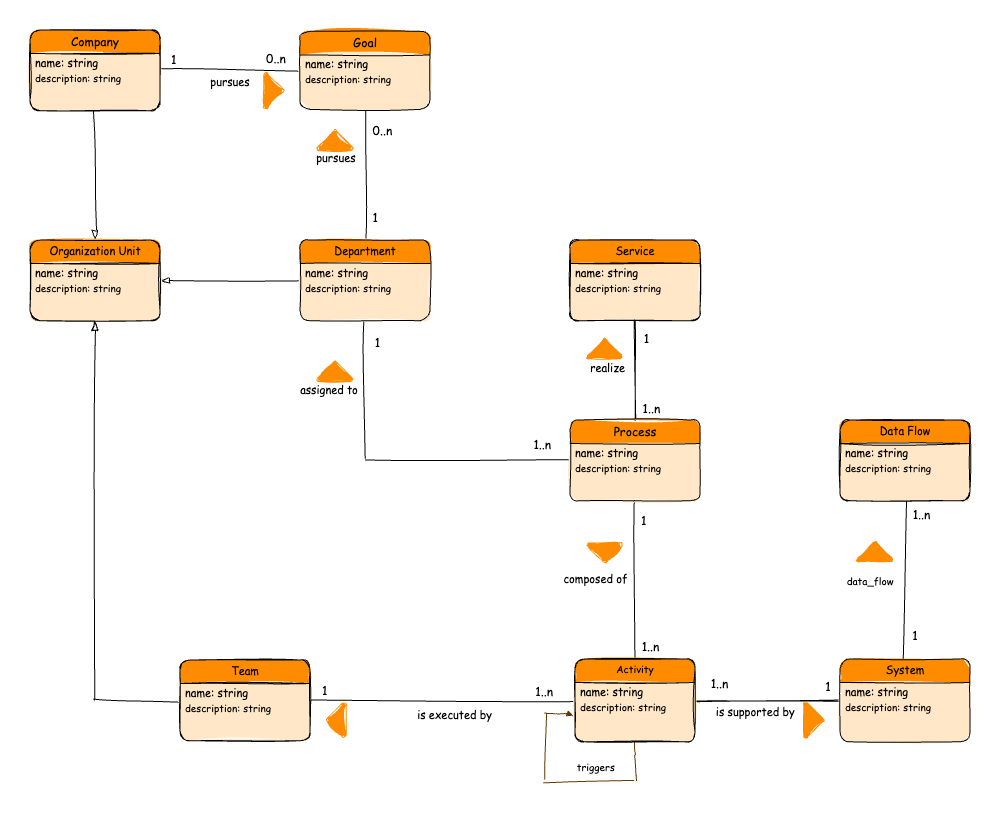
The first model contained only names and descriptions for each entity. It served as a common basis for thinking and a visual starting point for all further steps.
From Model To Dialogue: The Technical Implementation
The idea of a talking company is fascinating—but its implementation requires a well-thought-out technical foundation. To achieve this, three worlds had to be connected: structured knowledge, graph-based data storage, and generative AI.
Modeling With ArchiMate: The Visual Foundation
The starting point was our company model, which we created using the open-source tool Archi. Archi allows structured, visual models to be built based on the ArchiMate modeling standard—ideal for representing organizations, processes, IT systems, and their relationships with each other.

We deliberately stuck to a visually comprehensible, modular structure. This allowed us to adapt, expand, and add new elements to the model at any time—an important prerequisite for iterative work.
Graph Database With Neo4j: Structure Becomes Knowledge
In the next step, we automatically transferred the Archi model to a graph database. We use Neo4j for this.
Unlike relational databases, graph databases store information in the form of nodes and edges—perfect for mapping complex relationship networks and searching them quickly. Each node corresponds to an entity from our model (e.g., “process,” “team,” or “system”), and each edge to a semantic relationship (“executes,” “supports,” or “consists of”).
This representation transforms a simple data model into a knowledge graph—an initial version of a “digital twin” of our car-sharing company.
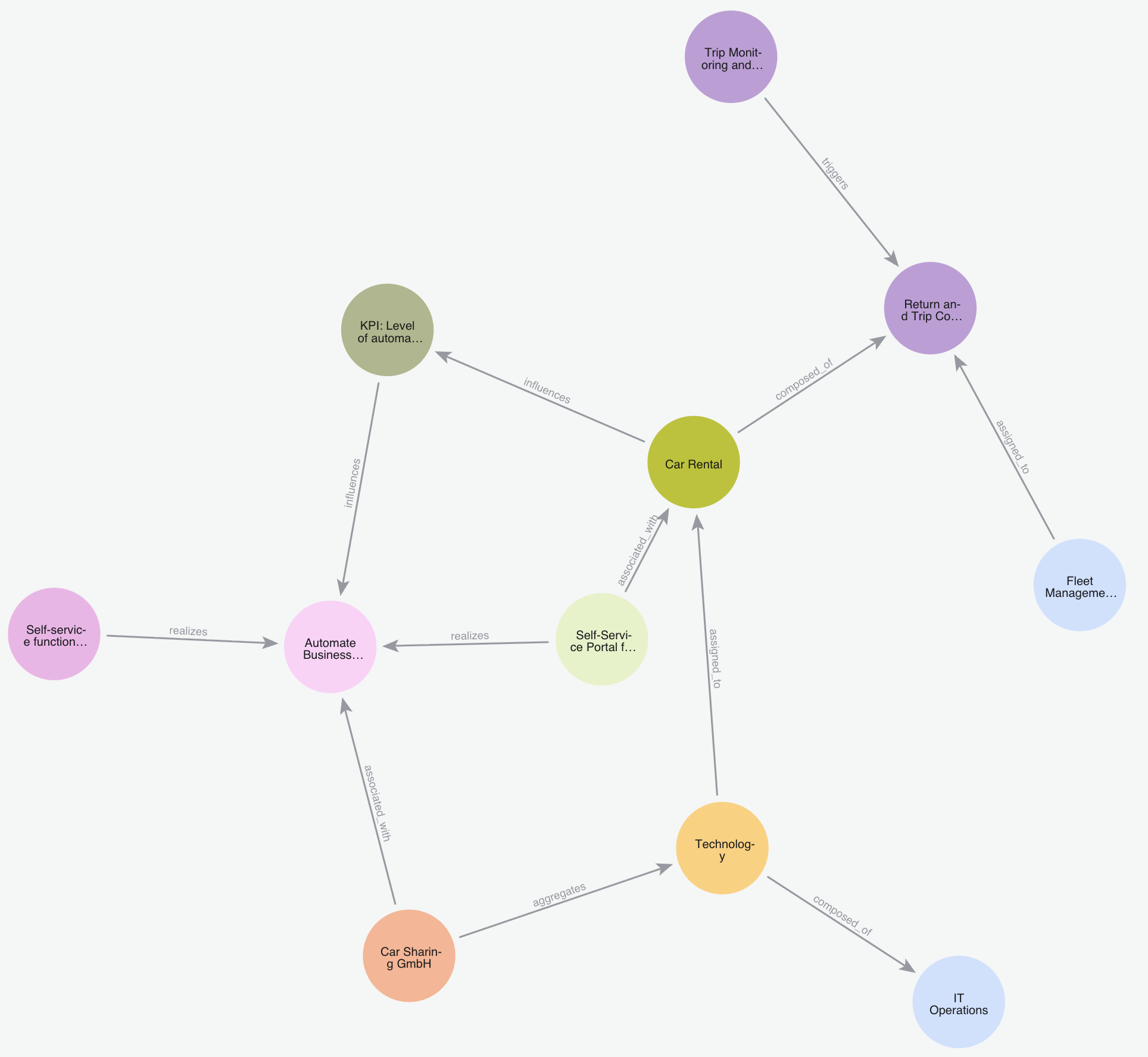
In Neo4j, the ArchiMate model becomes a living knowledge graph—all entities are semantically connected so that the AI assistant can interpret them in context.
Integration Of Generative AI: Language Meets Structure
The crucial step was connecting to a powerful language model—GPT5 from OpenAI. Using the OpenAI API, we enabled our enterprise AI navigator to access the contents of the knowledge graph.
But for the navigator to be truly useful, access alone is not enough: the navigator must search for the contextual information relevant to the question. To achieve this, we developed special prompts that tell the AI what kind of information is available. We essentially taught the AI our data model.
On this basis, the AI can then:
- Translate natural language queries into structured queries on the knowledge graph. The Neo4j graph database we use provides the Cypher query language; our Enterprise AI Navigator can formulate suitable Cypher queries from natural language questions because it knows and understands the data model.
- extracts the relevant information from Neo4j,
- and converts the results into understandable answers, supplemented by relevant cross-references.
On this basis, initial interesting questions can already be asked that go beyond a pure “full-text search”:
- “Which processes are currently documented in the company, and which ones are missing in your opinion?”
- “Show me all systems that support the ‘car rental’ process.”
Our Enterprise AI Navigator can already answer simple questions well with the data model shown above. But when it comes to more difficult questions, it reaches its limits:
- “Which processes are particularly well suited for automation?”
- “What happens if the ERP system fails?”
- “What corporate strategies do you recommend for achieving our cost-saving goals?”
The reason is simple: there is a lack of context—just like us humans, generative AI needs context-dependent information to be able to answer questions.
The First Use Case: Process Optimization
To increase the performance of our AI Navigator, we developed a specific use case: Which processes are particularly well suited for automation?
Even though we know from experience what information is needed to make decisions about process automation, we still asked the AI what information it thought was missing—it never hurts to get a second opinion.
This resulted in the following changes:
More Depth Through Additional Data
We added the following data to the activities:
- Execution type: manual, semi-automatic, or automatic.
- Frequency per month: how often an activity takes place
- Average processing time: how long it takes on average to complete this activity.
- Error rate: How often do technical errors occur when implementing the activity?
- Manual workaround: Can the activity be implemented manually in the event of a technical error?
- Workaround restriction: How significant is the restriction due to the workaround?
More Context Through Relationships
We had already taken many relationships into account in the original data model. In the course of further development, a relationship between activity and team was added.
“Performed by” → Relationship between activity and team
This allowed us to show for the first time who does what, how often, with what effort, and with what error rate.
In this way, we expanded our data model to include the first use case for process automation:
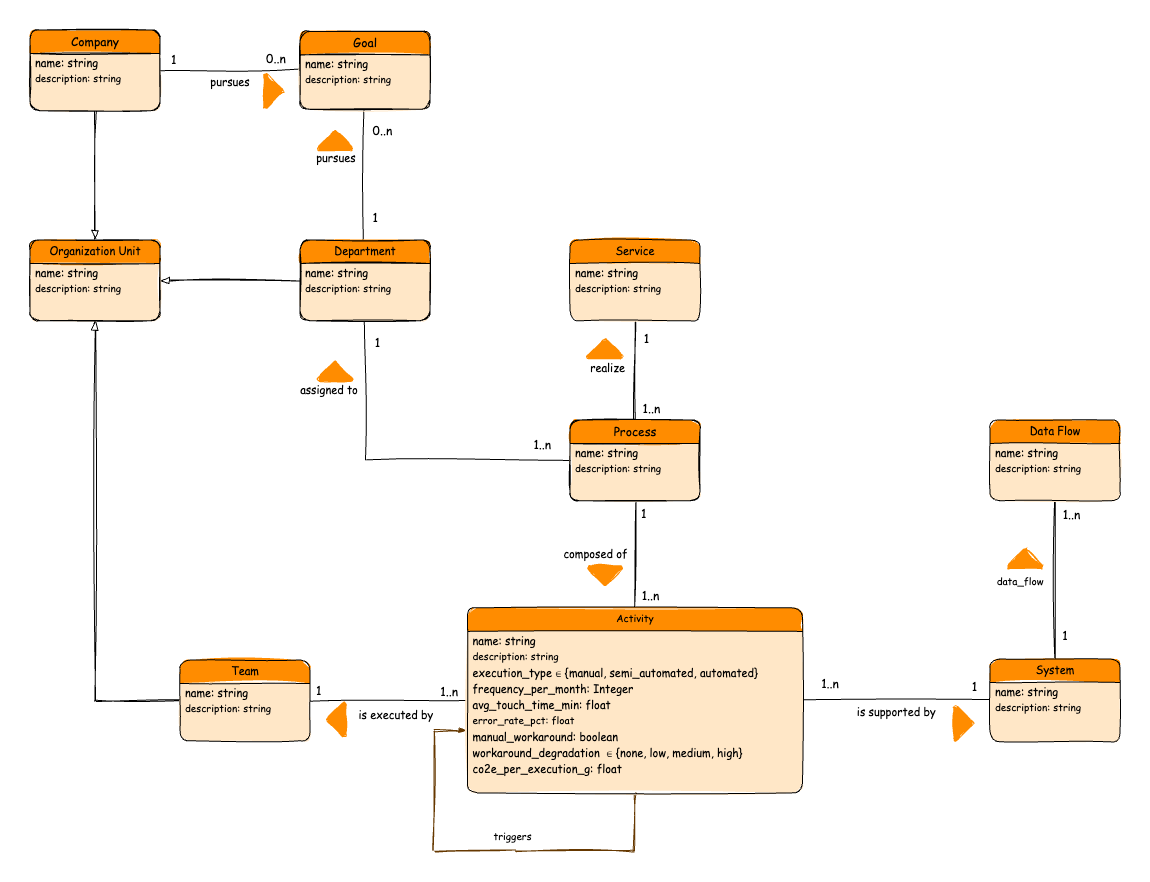
The new model is enriched with additional attributes and relationships—the basis for a semantic knowledge graph.
The Turning Point: Knowledge Instead of Structure
With the new attributes and relations, the assistant can now
- Prioritize processes in terms of their automation potential
- Evaluate effort, frequency, and error rate
- Identify and explain dependencies.
The system was now able to answer complex questions—and draw on well-founded data.
Curious?
Try it out for yourself: Visit our Car Sharing Enterprise Model to see the AI Navigator in action.
The Result: Process Intelligence Instead of Modeling
What began as a simple business model became an AI-supported knowledge system:
- A structured data core that systematically maps business knowledge
- A semantic graph that reveals connections
- A language interface that makes this knowledge interactive
- An assistant that not only displays but also recommends
Conclusion: Platform Instead of Prototype
This project has resulted in more than just a single use case. We have created a platform that serves as a starting point for numerous other applications:
- Goal achievement and strategy alignment
- Feasibility and impact analyses
- Decision support for complex issues
And best of all, the system is context-based, dialogue-oriented, and real-time.
Experience it for yourself.
Visit our showcase and discover how our system visualizes process knowledge and opens up new perspectives for automation, optimization, and decision support.
Table of Contents
- Our Vision: An Enterprise Digital Twin You Can Actually Talk To
- The Starting Point: Many Questions, One Goal
- The First Model: Simple But Structured
- From Model To Dialogue: The Technical Implementation
- The First Use Case: Process Optimization
- The Result: Process Intelligence Instead of Modeling
- Conclusion: Platform Instead of Prototype



Services
Resources
All Rights Reserved.