
Generative AI That Understands Your Enterprise
See Your Enterprise Like Never Before
Oliver Grasl
23.9.2025
GenAI can be made far more valuable for enterprise transformation by connecting it to knowledge graphs that capture specific organizational context.
Like everyone else, we've been thinking about how to use GenAI (generative AI) in our work.
We help our clients use the power of digital technology to make their products, business models, and processes smarter.
We do this with our tried-and-true transformation methodology, which doesn't just change businesses; it reimagines them. Furthermore, we solve hard problems for organizations by combining the creative power of design thinking, the wisdom of systems thinking, and the precision of computational thinking.
How can GenAI help us do this even more effectively, then?
We thought long and hard about how we could incorporate GenAI into our transformation methodology:
- What if we could have a conversation with our client's entire business?
- What if every strategy session started with perfect knowledge of how every piece of their organization connects, competes, and creates value?
- What if we could combine the unique knowledge in the heads of our clients and our consultants with the power of GenAI?
- What if we could discuss the potential impact of a transformative change not only with our clients but also with GenAI?
Our approach is to let AI do the heavy lifting of research and analysis, freeing us to focus on what humans do best: creative problem-solving, strategic insight, and building meaningful connections with our clients.
Providing Context via Knowledge Graphs
Like most people, we use GenAI for general research.
But what we would really like to do is to have deep conversations about the enterprises we are working with to identify concrete levers for performance improvement.
For this to work, we need to provide the relevant context information to the GenAI, because GenAI has no inherent, up-to-date knowledge of a specific enterprise's inner workings.
Enterprise transformation is a long-running endeavor; hence, the information we have about an enterprise is permanently evolving and changing as we gather new facts about it.
How then can we provide context to GenAI in this case?
In principle, we could upload the context in a document, but because the context information is constantly changing, maintaining such a document is quite cumbersome, even without GenAI.
So from the outset, our methodology has always been “model-driven,” using visual models to capture and visualize information about our clients' enterprises.
One advantage of visual models is that they provide intuitive diagrams that facilitate discussions with stakeholders.
But the key advantage of models is that they aren't just visualizations: models have structure and semantics, and because of this, they can be read and manipulated by machines. This allows us to analyze the information in models in many ways, and we can answer many questions about an enterprise by “querying the model.”
Given that these models provide great decision-making context to us and our clients, why not use them as context for AI?
For this to work, we need to make the model “query-able” not only for humans but also for AI so that the AI can decide which information from the model to use to answer a particular question.
Of course we don't want to give up what is good about our current approach: speaking to stakeholders, gathering relevant information, building models, and feeding information and insights back to all stakeholders to build shared understanding. Doing this is important not only because it helps our clients to make better decisions in complex situations but also because it facilitates change.
Hence we need to find a way to capture what we learn and to provide that information back to stakeholders (to build shared understanding) and to Gen AI (as context for meaningful analysis).
Fortunately for us, there exists a whole class of databases that are similar to visual modeling platforms but also provide query languages and APIs: graph databases.
So here is our approach:
- First, capture the information we have about an enterprise in a visual model (no change there).
- Sync the information we have in our model into a graph database, thus creating a knowledge graph of the enterprise—this is straightforward to do because this can be automated.
- One advantage of having a graph database is that you can make them available via an API and can query them.
- Another advantage is that we can extend the data in the graph database with “live” data from the enterprise—this is compelling and is something you cannot easily do with models themselves.
- Now that we have the information in a knowledge graph, we can make that information available to GenAI, thus implementing Retrieval-Augmented Generation (RAG).
- This effectively means that we can now use GenAI to reason about an enterprise interactively, much like we would reason about it with other human beings.

I know this all sounds quite abstract, which is why we have built a little showcase to illustrate this approach—you can check it right now on app.metapad.ai:
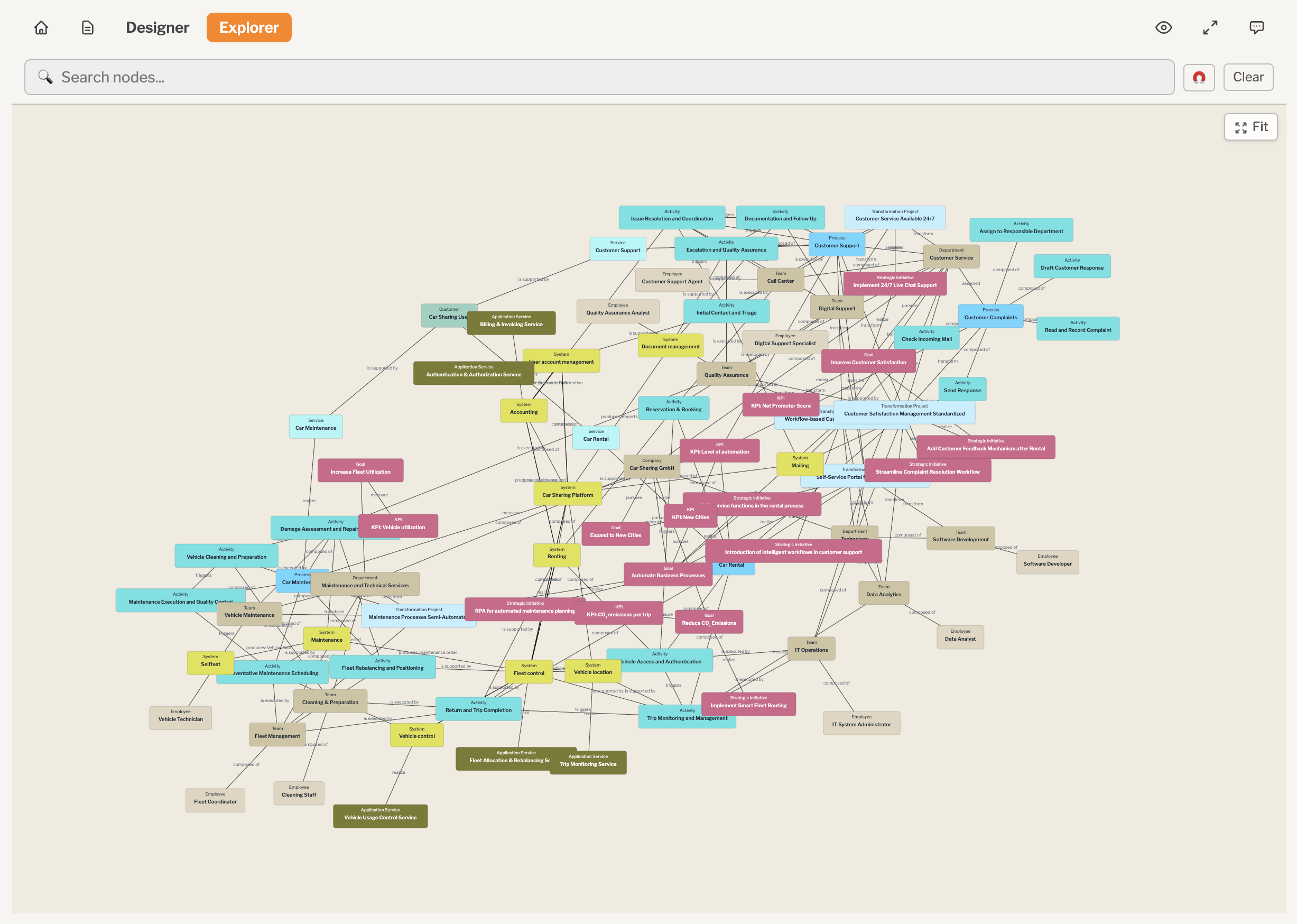
- The showcase is built around a model of a fictional car-sharing enterprise.
- The model captures the enterprise's goals, services, processes, organizational structure, and IT landscape.
- The model is automatically replicated into a graph database, which is connected to an AI chat agent for retrieval-augmented generation.
The website lets you browse through the enterprise to take a closer look at its structure, processes, and IT landscape.
The website also provides an AI chat assistant that lets you chat with GenAI about the enterprise and ask simple questions like “Which systems support the car rental process?” or “Which processes are affected if the fleet management system fails?” (effectively using the AI assistant as an augmented search engine), but also more sophisticated questions such as “We'd like to consolidate our IT landscape—can you please check the list of IT systems and provide a suggestion?”
Please play with the showcase right now to see it in action, then come back here to read about how it works.
How It Works
Let's take a closer look at how the AI assistant works and how it accesses the car-sharing knowledge graph.

There are four components that interact to provide the transentis.ai service:
- The website itself, which lets you browse through the car-sharing model, provides an AI chat assistant and also visualizes the data retrieved from the knowledge graph. We use Nextra.js to build the website.
- the knowledge graph, which captures information about the building blocks of the car-sharing enterprise and how they relate to each other. We use the Neo4j Aura graph database to host the knowledge graph.
- the car-sharing AI agent, which handles the chat requests and passes them on to OpenAI for processing and also retrieves data from the knowledge graph if necessary. This is a custom web service built using Python. We use typst for report generation.
- the LLM (large language model), provided by OpenAI (we use GPT-5)
What happens when you enter a prompt such as “Please list all processes in the knowledge graph”?

- The prompt is passed from the chat box on the website to the chat assistant web service.
- The chat assistant passes the prompt on to GPT-5 on OpenAI, along with a description of the knowledge graph (the so-called metamodel or schema of the knowledge graph, which defines what kind of information is in the knowledge graph and how it is related, e.g., processes, the departments that own the processes, the teams that make up the departments, …).
- GPT-5 analyzes the prompt and understands that the prompt is about retrieving information from the knowledge graph. Because it knows about the knowledge graph metamodel (thanks to our prompt) and because GPT-5 can speak Cypher (the language used to query graph databases), it turns the prompt “Please list all processes in the knowledge graph” into a corresponding Cypher query.
- The Cypher query is passed back to the car-sharing AI agent.
- The car-sharing AI agent queries the knowledge graph using the Cypher query and retrieves the data from the graph database.
- The chat assistant passes the information back to GPT-5.
- GPT-5 formats the data and returns the formatted data to the car-sharing AI service.
- The car-sharing AI agent passes the information back to the chat box on the transentis.ai website.
- The chat box displays the information and waits for the next prompt.
This sequence of steps is an illustration of retrieval-augmented generation (RAG)—the important point is that GPT-5 and OpenAI cannot directly access the knowledge graph; GPT-5 just formulates the relevant queries, and the car-sharing AI agent handles data retrieval and decides which data to pass on to GPT-5.
GPT-5 never sees all the data at once, only the part that is relevant to answering the prompt.
Next Steps
Now that we have a knowledge graph of the car-sharing enterprise that is connected to AI, the interesting question is, how can GenAI now help us to explore, redesign, and transform the car-sharing enterprise?
You can already experiment with this on app.metapad.ai
Here is a simple sequence of questions you could ask:
- Please list all systems in the knowledge graph
- We would like to consolidate our IT landscape. Given the list of systems, can you provide a suggestion of how to do this?
Another interesting approach is to ask questions about what is missing—e.g., as it stands, the car-sharing model only shows the core processes of a car-sharing enterprise; therefore, the following sequence of prompts delivers interesting results.
- Please list all processes in the knowledge graph
- Please analyze this list of processes and let me know which processes are missing from the perspective of a car-sharing enterprise.

Services
Resources
All Rights Reserved.