
Infrastruktur-Simulation
Ein Agent-basierter Ansatz

Dominik Schröck
Tuesday, November 12, 2019
Eine Untersuchung eines eigenen alternativen Ansatzes unter Verwendung agentenbasierter Simulationen und des BPTK-Py-Rahmens für die Modellierung von IT-Infrastruktur-Simulationen
Die Dimensionierung von Servern und Infrastruktur ist ein häufiges Problem bei großen IT-Projekten. Es endet in der Regel mit großen, komplexen Tabellenkalkulationen und vielen Variablen, die in irgendeiner Weise die Kosten und die Ressourcenauslastung beeinflussen. Für jedes Projekt müssen Sie die Kosten- und Ressourcentreiber identifizieren und ihren Einfluss auf das Gesamtsystem definieren. Dieser Ansatz ist mühsam und ermüdend und lässt die Dynamik der Systeminteraktion vermissen und kann eine große Anzahl verschiedener Szenarien und deren Auswirkungen auf die Infrastruktur nicht abdecken.
In diesem Blogpost möchten wir zeigen, wie wir unser eigenes Simulations-Framework BPTK-PY für die Modellierung von IT-Infrastruktursimulationen verwenden. Wenn Sie noch nichts über das Simulations-Framework gehört haben, finden Sie Computational Essays auf Basis von Simulationsmodellen schreiben Informationen zu BPTK-PY.

Eine IT-Infrastruktur ist eine Sammlung von Systemen, die miteinander interagieren - normalerweise in Form eines Datenflusses. Jedes System hat Eigenschaften wie z.B. eine maximale Kommunikationsgeschwindigkeit (z.B. 1 GBit/s für eine Ethernet-Schnittstelle) oder Speicher-/Speicherbeschränkungen.
Um Engpässe zu identifizieren und die tatsächlichen Kosten abzuschätzen, benötigen wir eine Simulation, die diese Einschränkungen und den Datenfluss innerhalb Ihrer Infrastruktur berücksichtigt. Mit unserem Ansatz modellieren wir die Infrastruktur als einen Graphen von Systemen. Kanten bezeichnen den Datenfluss, während Knoten die beteiligten Systeme beschreiben (Recheneinheiten, Anwendungen, Datenströme...).
Mit BPTK-Py können Sie solche Simulationen einfach definieren. Aus diesem Grund haben wir uns entschieden, gemeinsame Systeme in einer Infrastrukturumgebung vorzudefinieren und es Ihnen leicht zu machen, sie miteinander zu verbinden.
Vorerst stehen folgende Systeme zur Verfügung:
- Eingabe: Datenstrom der eingehenden Elemente, auch Quelle genannt. Erzeugt Elemente in einer Sinusfunktion, die sich um einen Mittelwert herum befinden. Output sind die produzierten Daten in MB
- Kinesis-Strom: AWS Kinesis Stream, der einen Input akzeptiert und einen Output erzeugt.
- Ziel: Empfänger der verarbeiteten Ereignisse
- Lambda: AWS-Lambda-Funktion, hauptsächlich zur Datentransformation verwendet
- Load Balancer: Verteilt den eingehenden Strom auf Berechnungseinheiten
- Berechnen: Diese Einheiten verarbeiten die Daten und geben die verarbeiteten Daten an die Zielperson(en) aus. Sie verfügen über einen Speicher und Speicherplatz. Sie empfangen eingehende Ereignisse und geben eine feste Anzahl von Ereignissen pro Zeitschritt aus. Sie können auch Daten ablehnen, wenn Speicher und Speicher voll sind.
- Abfrage: Ziehen Sie regelmäßig Daten aus einem anderen System, z.B. einer anderen Compute Unit, die eine Datenbank repräsentiert.
Targets, Load Balancer und Compute haben Warteschlangen (bei Compute sind dies Speicher und Arbeitsspeicher). Wenn die Warteschlangen voll sind, lehnen sie Daten ab und kehren zum Absender zurück. Die Ereignisse werden dann dem empfangenden Agenten hinzugefügt oder zurückgewiesen und an den vorherigen Agenten zurückübertragen. Auf diese Weise können wir mögliche Engpässe erkennen und reagieren.
Um die Infrastruktur zu modellieren, haben wir eine sehr einfache Sprache geschaffen, die es Ihnen erlaubt, solche Modelle zu erstellen:

Das Simulationsmodell
Sie können Ihr Modell in YAML-Dateien beschreiben, den Rest erledigt unser Framework.
In dieser Simulation entspricht jeder Zeitschritt einer Sekunde. Auf diese Weise sind wir in der Lage, die genauesten Kosten- und Leistungszahlen zu simulieren. Allerdings können Simulationen recht lange dauern.
Beginnen wir mit der Definition unseres Simulationsmodells. Der erste Schritt besteht darin, die YAML-Modelldatei zu erstellen, die die Haupteigenschaften und 1 Szenario enthält.
Modell:name : Infrastruktur
Das Modell beginnt mit der Mustererklärung. Jedes Simulationsszenario verwendet dieses Modell. Als nächstes geben wir diesem Modell einen Namen: "Infrastruktur".
Jetzt können wir mit der Definition unseres ersten Szenarios beginnen. Die grundlegenden Eigenschaften sind die Startzeit, die Dauer und die Schrittweite (dt). Wir öffnen eine Liste von
und fügen das Szenario Job1 hinzu:Szenarien
- Job1:starttime : 0duration: 3600dt : 1
Die Szenarien laufen unabhängig voneinander ab. Auf diese Weise können Sie die Ergebnisse aus verschiedenen Konfigurationen miteinander vergleichen.
Nun wollen wir Knoten hinzufügen. Die folgenden Zeilen fügen die Knoten für zwei Datenpipelines hinzu, die nebeneinander verlaufen:
nodes:- INPUT:type : data_inputcount : 1step : 1target : STREAMaverage_output : 80- STREAM:count : 1step : 1type: kinesisprevious: INPUTtarget: LOADBALANCERcost_shard_hour : 0.018average_output : 20shards : 80max_shards: 100- LOADBALANCER:count : 1type: load_balancerprevious : STREAMtarget : COMPUTE- COMPUTE:count : 2step : 1previous : LOADBALANCERtarget: TARGETtype : compute- TARGET:type : targetcount : 1step : 1previous: COMPUTEmax_queue: 1000000- INPUT_2:type: data_inputtarget : STREAM_2- STREAM_2:type: kinesistarget: LAMBDAprevious: INPUT_2- LAMBDA:type: lambda_functiontarget: DATABASEprevious: STREAM_2- DATABASE:type: computestorage_size: 1048576previous: LAMBDAtarget: QUERY- QUERY:type: queryprevious: DATABASE
Schauen Sie sich die Typdeklaration an. Diese Direktive ist für vorkonfigurierte Knoten mit Standardkonfigurationen verfügbar.
Die erste Datenpipeline ist die im obigen Diagramm dargestellte. Sie wird mit einer Kinesis-Quelle, einem Load Balancer, 2 Recheneinheiten und einem Ziel-Agenten geliefert. Beachten Sie, dass die Zähleinstellung der COMPUTE-Einheiten gleich zwei ist. Das bedeutet, dass die Systemgruppe COMPUTE aus einem Cluster von zwei virtuellen Maschinen besteht. Die zweite Pipeline simuliert eine verteilte Datenbank, die mit Rohdaten gespeist wird, die über einen Kinesis-Strom geliefert werden. Die Vorverarbeitung für die Datenbank erfolgt mit einer AWS-Lambda-Funktion.
Die QUERY-Komponente simuliert Abfragen, die gegen den Datenbank-Cluster laufen. Tatsächlich simulieren wir die Datenbank als einen weiteren Satz von VMs, die eine Anwendung ausführen, mit einem größeren Speicher von jeweils einem Terabyte. Tatsächlich unterstützt unsere Simulation sogar die Simulation der Lese- und Schreibgeschwindigkeit des Speichers in MByte/s.
Beide Jobs laufen im selben Szenario. Dies ermöglicht uns die Simulation von mehreren Pipelines, die möglicherweise miteinander interagieren.
Jedes System wird mit einem vordefinierten Satz von Eigenschaften geliefert. Sie können diese überschreiben, so wie wir es z.B. für average_input des INPUT-Knotens getan haben. Die Simulation erzeugt einen Eingang, der einer Sinuswelle ähnelt und um einen Mittelwert herum schwebt. Warum? Weil wir auf diese Weise unterschiedliche Belastungen simulieren können. Wir haben eine durchschnittliche Ausgabe von 80 MByte/s konfiguriert.
Die Optionen Vorgänger und Ziel verbinden die Knoten miteinander. Auf diese Weise konstruieren wir die Infrastruktur als einen Graphen, wobei die Daten vom Input zum Output fließen.
Das Modell ist bereit für die Simulation. Bevor wir die Simulation ausführen, ist es hilfreich, die Datenpipeline als ein Diagramm zu visualisieren. Lassen Sie uns das Modell schnell visualisieren, bevor wir die Simulationsergebnisse analysieren:
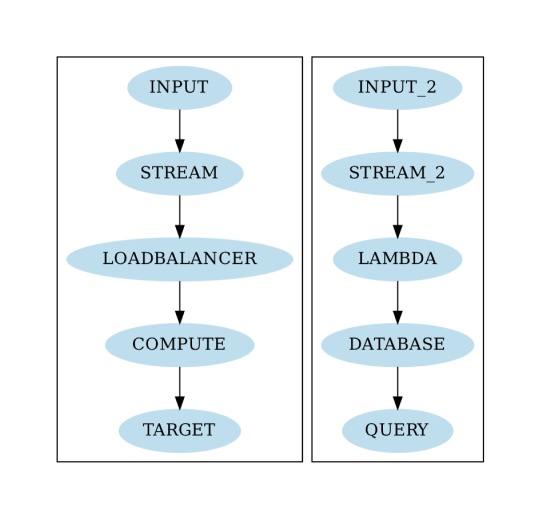
Ausführen des Modells
Jetzt können wir loslegen und Standardfunktionen aus
zur Durchführung der Infrastruktursimulation verwenden. Zunächst werden wir den Kinesis-Strom überprüfen, der die Eingangsdaten für die Datenpipeline liefert.BPTK-PY
Der Kinesis-Strom passt die Anzahl der Scherben in einem bestimmten Intervall an. Ein Shard hat einen maximalen Input von einem MB/s und einen Output von zwei MB/s. Die Standardeinstellung für die Eigenschaft
beträgt 60 Sekunden. Sie können diese Eigenschaft nach Belieben ändern. Für das Resharding verwenden wir die durchschnittliche Eingabe, um die Anzahl der Shards zu berechnen:reshard_interval
shards = min( max( max_input, current shards), max_shards)
Der
ist der maximale Input, der während der letzten reshard_interval-Perioden beobachtet wurde. Wir setzen max_shards in der Konfiguration auf 100 (siehe oben).max_input
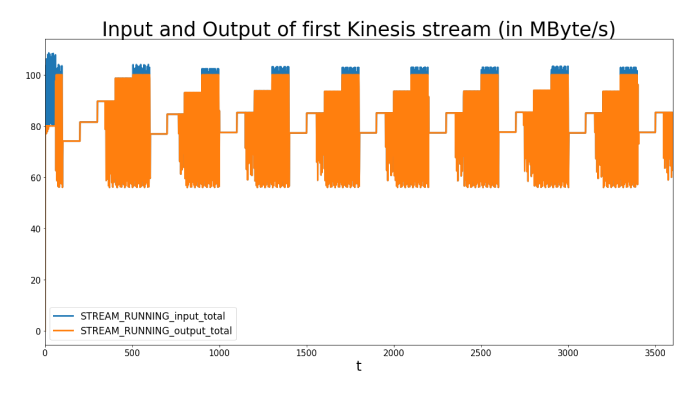
Die folgende Grafik (übrigens wurden die Grafiken hier ursprünglich mit BPTK-Py erstellt) zeigt die Anzahl der Shards und den Input/Output pro Sekunde in MByte. Der Input steigt schnell an, gefolgt von einem starken Rückgang, nach dem er um 80 MB/s schwankt. Dies ähnelt sehr stark der Sinuswelle, die durch den Input erzeugt wird. Der Input ist immer höher als der Output, da die Anzahl der Shards auf 100 begrenzt ist, was zu einer maximalen Input-Rate von 100 MB/s führt. Zusätzliche Ereignisse werden zurückgewiesen und an den Input zurückgegeben. Der Eingang reagiert darauf und wird langsamer. Dies führt zu einem Gleichgewicht von Input und Output des Kinesis-Stromes. Der Dateneingabe-Agent reagiert darauf, indem er seine Ausgabegeschwindigkeit wieder langsam erhöht, bis er seine Warteschlange abgearbeitet hat und die Daten wieder fast in Echtzeit senden kann. Der Kinesis-Strom kann jedoch aufgrund der Shards-Beschränkung nicht aufgenommen werden und muss Ereignisse erneut zurückweisen, was zu einer Wiederholung dieses Musters führt.
Wir können daraus schließen, dass die maximale Anzahl von Shards für einen optimalen Datenfluss etwas zu gering ist. Ob dies akzeptabel ist, ist natürlich immer eine geschäftliche Entscheidung.
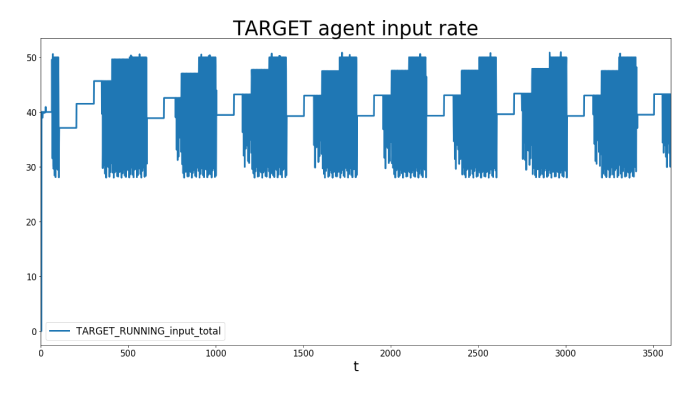
Schauen wir uns nun das andere Ende der Pipeline an, das TARGET-System bzw. die TARGET-Anwendung. Wir beobachten dasselbe Muster wie zuvor, nur mit niedrigeren Werten. Der Grund dafür ist, dass das Input/Output-Verhältnis der Kinesis-Einheiten auf 0,5 eingestellt ist, was bedeutet, dass pro 1 MByte Input 0,5 MByte ausgegeben werden. Lassen Sie sich nicht verwirren: Die gemessenen Zahlen in der obigen Grafik zeigen die Anzahl der verarbeiteten Bytes im Vergleich zu den Eingabedaten, um die Zahlen vergleichbar zu machen.
Es ist interessant, die Dynamik zu beobachten, mit der die Datenpipeline ihre Geschwindigkeit an das langsamste Element, in diesem Fall den Kinesis-Strom, anpasst. Insbesondere das Muster der Eingangsquelle, die ihre Geschwindigkeit regelmäßig anpasst, ist interessant. Unser Ziel ist es, die Datenausgabe unter Beibehaltung der Kosten auf die maximale Geschwindigkeit der Zielobjekte zu erhöhen.
Vielleicht möchten Sie die Anzahl der Recheneinheiten auf ein Minimum reduzieren, um die Kosten zu senken. Aber bedenken Sie, dass Sie in Wirklichkeit vielleicht Redundanz garantieren wollen. In diesem Beispiel könnte 1 statt 2 Recheneinheiten ausreichend sein. Auf der anderen Seite haben wir nur eine Stunde simuliert. Es könnte spannend sein, die Simulation viel länger laufen zu lassen, um die Auswirkungen auf die Speicher- und Speicherauslastung der VM zu sehen. Insbesondere könnte die verteilte Datenbank im zweiten Job irgendwann voll laufen, so dass dem Cluster ein weiterer Knoten hinzugefügt werden muss.
Kosten
Nachdem ein optimaler Aufbau gefunden wurde, ist es an der Zeit, den Kostenfaktor zu analysieren, der für Geschäftsentscheidungen für oder gegen eine Infrastruktur am wichtigsten ist. Jeder Knoten definiert seine eigene Kostenfunktion und speichert die für jede Runde anfallenden Kosten. Nachdem die Datenpipeline verbessert und ein optimales Setup gefunden wurde, können wir einen Blick auf die Kosten und Kostentreiber werfen. Ein Vorteil der Simulation im Vergleich zur statischen Kostenanalyse mit z.B. Tabellenkalkulationen ist, dass die Kosten der Dynamik des Gesamtsystems und seiner Wechselwirkungen ähneln. Diese Systemsicht ermöglicht es Ihnen, einen optimalen Kompromiss zwischen Kosten und Leistung zu finden.
Das folgende Tabelle zeigt die Kosten der einzelnen Agenten, gefolgt von einer Summe nach den gesamten 3.600 Sekunden für jeden Agenten.

Und hier kommt die Grafik für die Systemkomponenten mit den Gesamtkosten pro Sekunde:
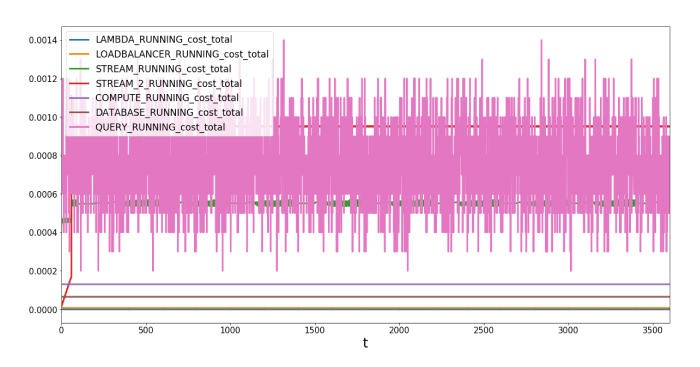
Die Kosten für das QUERY-System schwanken um 0,0009 US-$ pro Periode. Was nicht verwunderlich ist, da es darüber entscheidet, wie oft Daten gegen die Datenbank mit einer zufälligen, gleichmäßig verteilten Zahl abgefragt werden.
Wir haben die Eingabe- und Zielanwendung weggelassen, da wir für sie keine Kostenfunktionen definiert haben, was zu konstanten Kosten von 0 führt. Sie können jedoch die Grundstückskosten direkt einstellen, um konstante Kosten zu simulieren und in Ihre Bilanzberechnungen einzubeziehen. Unsere Gründe dafür, wie die Kosten dieser Systeme funktionieren, liegen darin, dass sie als Dummy für alle Systeme fungieren, die außerhalb des Rahmens dieser Simulation liegen. Wir brauchen nur ihre Warteschlange und andere Eigenschaften, um den Datenfluss zu simulieren und Engpässe zu identifizieren. Sie können jedoch die Kosteneigenschaft festlegen, was zu konstanten Kosten pro Runde führt.
Wir beobachten die höchsten Kosten für die QUERY-Agenten. Dies ist darauf zurückzuführen, dass wir eine relativ hohe
von 0,0001 $ festlegen. Sie können dies durch eine Neukonfiguration des Jobs reduzieren. Die beiden Kinesis-Streams sind ebenfalls relativ teuer, mit mehr als 5 USD für eine Stunde.cost_per_query
Mehr Komplexität: Ausfall und Neustart von Systemen
In realen Umgebungen fallen Maschinen hin und wieder aus. Es ist schwierig, die Auswirkungen solcher Szenarien mit Hilfe von Tabellenkalkulationen richtig zu simulieren. Wir haben spezifische Modellereignisse, das
-Element, hinzugefügt. Es kann den Zustand eines Knotens von einem Zustand in einen anderen ändern. Wenn es ausgelöst wird, wählt es zufällig einen Knoten, der sich im Zielzustand befindet, aus der Gruppe der Zielknoten aus und ändert den Zustand.change_state
Es verfügt über 2 Modi:
- FIXED: Triggert zu einem bestimmten Zeitpunkt und ändert den Zustand eines Knotens in den Zielzustand
- RANDOM: Triggert in regelmäßigen Abständen und entscheidet nach dem Zufallsprinzip über seinen
Parameter, ob er den Zustand ändertlikelihood
Werfen wir einen Blick auf ein weiteres einfaches Beispiel (zur besseren Lesbarkeit gekürzt):
Model:[...]nodes:- FAIL:type: change_statetarget : COMPUTEmode: FIXEDtrigger_at : 200state_map : {'RUNNING' : 'FAIL'}- RESTART:type: change_statetarget: COMPUTEmode: FIXEDtrigger_at: 2000state_map: {'FAIL': 'RUNNING'}[...]
In diesem Szenario setzen wir zwei neue Knoten ein:
undRESTART
, die beide vom TypFAIL
sind.change_state
setzt den Zustand einesFAIL
-Knotens zur Zeit 200 aufCOMPUTE
FAIL.
wird zum Zeitpunkt 2000 das Gegenteil bewirken. Der ParameterRESTART
ist wichtig, da er konfiguriert, von welchem Zustand in den Zielzustand gewechselt werden soll. Beispielsweise wählt der Parameterstate_map
einenFAIL
node aus, der sich im Zustand RUNNING befindet, und ändert ihn in FAIL.COMPUTE-
Jetzt können wir mit diesem Beispiel herumspielen und analysieren, was vor und nach dem Fehlschlag geschieht. Werfen wir einen Blick auf die Ein-/Ausgaberate der COMPUTE-Einheiten:
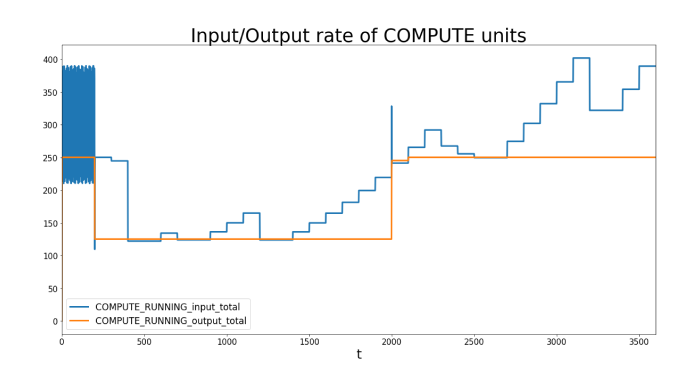
Wir beobachten eine konstante Ein-/Ausgaberate bis zur Zeit = 200, wenn eine COMPUTE-Einheit ausfällt. Die Eingabe löst jedoch weiterhin Ereignisse aus, während die Ausgabe der COMPUTE-Einheit abnimmt, da nur noch eine übrig bleibt, mit einer maximalen Ausgabe von 1 GBit/s (125 Mbyte). Nach einer Weile reagiert der INPUT-Knoten auf die neue Situation und reduziert ebenfalls seine Ausgaberate, während er weiterhin versucht, regelmäßig zu erhöhen. Zum Zeitpunkt 2.000 ist die zweite COMPUTE-Einheit wieder einsatzbereit, was zu einer sofortigen Erhöhung der Ausgaberate auf das Maximum von 250 MByte/s führt.
Der Eingangsstrom erhöht seine Geschwindigkeit jedoch nur langsam in regelmäßigen Abständen und prüft, ob er Ablehnungsereignisse erhält, bevor er weiter ansteigt.
Fazit
Die Modellierung dynamischer Systeme hilft Ihnen, sehr komplexe Interaktionen zwischen Elementen Ihrer Umgebung zu simulieren und gibt Ihnen Einblicke, die Sie mit statischen Methoden wie Excel niemals erhalten würden. Mit der Simulation können Sie Engpässe leicht erkennen, die Systemleistung verbessern und die Auswirkungen von Randfällen wie Systemabstürzen vor der Bereitstellung analysieren. Das Ergebnis ist eine Karte Ihrer zukünftigen Software- und Hardware-Umgebung.
Dieser Blogpost demonstrierte die Fähigkeiten unseres eigenen Simulations-Frameworks in Bezug auf Infrastruktur-Simulationen. Vordefinierte Systeme als Bausteine mit veränderbaren Standardkonfigurationen ermöglichen einen einfachen Modellaufbau. Mit unserem konfigurierbaren Ansatz ist es einfach, sehr komplexe Datenpipelines ohne allzu großen Aufwand zu entwerfen. Das bedeutet, dass Sie sich auf die Analyse und Optimierung konzentrieren können, anstatt sich mit der Modellerstellung befassen zu müssen.
In diesem kleinen Beispiel haben wir modelliert:
- Dynamische Skalierung von Kinesis-Strömen
- Automatische Anpassungen der Datenraten von Datenpipelines mit Hilfe von Warteschlangen, ähnlich dem Verhalten in der realen Welt
- Komplexe Kostenfunktionen, einschließlich ziemlich genauer Kostenfunktionen für AWS-Komponenten
- VMs mit Hardware-Beschränkungen (HD-Lese-/Schreibgeschwindigkeit und Speicher)
- Simulation von Ausfall-Szenarien
Services
Workshops
Ressourcen
All Rights Reserved.